Have you ever found yourself in one of these team retrospectives, where everyone is trying to figure out why everything went wrong?
You’ve missed your iteration goal for the second time in a row, with last-minute changes, unstable releases, and ad-hoc requests piling up. Frustration and confusion start spreading all over the room.
If you’re an engineer, you’ve been through this more than once and would be all too familiar with how much the role of your product manager shaped the team’s efficiency and morale when times were tough. Over the past nine years, I’ve been working almost every day with product managers and owners on products meant to make people’s lives easier. As an engineer,
I always find it challenging for product managers to keep a balance between managing technology and managing people. I’ve witnessed a lot of missed opportunities for teams to produce timely and quality outcomes and results for the products they worked on, although these teams had plenty of great talents with solid experience under their belts.
So how can you do better as a product manager to unleash the full potential of your team?
Here are 10 winning characteristics the best product managers have in common.
1. They make themselves available to their teams.
Most of us had the chance to work with those product managers who were so busy that they rarely came to our stand-ups, didn’t reply to Slack threads, and never attended retrospective meetings. They prepare just enough for other scrum events like pre-planning, backlog refinement, and sprint planning meetings, and that’s fine. The problem is that in many cases,
it is necessary to have a responsive product manager who can give the team answers and guidance as needed during the sprint. We never assume that within two to three weeks, we’ll have a well-defined scope with clear acceptance criteria. The best product managers always make time to participate in ad-hoc calls or to respond to a thread in which the front-end and back-end engineers argue about something.
2. They ask the right “Why?” questions and bring solid problem statements to the team.
Product and engineering teams may find themselves frequently asking, “What do we need to build next?” as they have numerous boards piled high with features and requirements waiting to be picked. However, product excellence is not determined by the quantity of items delivered; it is determined by the value these items add to consumers and other stakeholders. That’s why it is essential to take a breather every so often and switch from asking “what?” questions to “why?” questions whenever possible.
Experienced product managers never present their teams with solutions but rather with problem statements. For instance, instead of being asked to implement a user provisioning feature using CSV sheets, the team working on the B2B product should instead hear about the problems that the users are having when it comes to onboarding new corporate customers. Clear problem statements let the team use their creativity,
product knowledge, analytical and critical thinking skills, and other skills to solve problems and come up with good ideas. Delivering features alone won’t solve issues; providing value will. Because of this, it is a product manager’s responsibility to conduct appropriate discovery and requirement gathering to enhance the conversations they have with their teams. That should lead to a list of possible solutions that can be put into action to solve the problem that was already mentioned.

3. They don’t turn their products and teams into “feature factories”.
A “feature factory” is a product or company that measures output over outcomes. It’s a story point machine where the company only cares about how much is being shipped. The company celebrates the work done, and it feels like a conveyor belt going in one direction. No one is thinking about the question: is any of this working? No one is thinking if any of this complexity is adding business value.
Occasionally, in feature-factory teams, feedback on the deliverables is provided without the participation of the individuals who worked on them. Customers, stakeholders, and product managers all participate in the feedback loop. A good product manager will ensure that their team is kept in the loop at all times. It’s always important to make sure that engineering teams can see the organization’s goals,
the metrics used to measure how well the results are working, and the direction that each of them should be going in. Whenever they see the benefit in including the engineering teams in stakeholder discussions, they make sure to do so without overburdening them.
They keep giving feedback on what the team did, celebrate when things go well, and give the team the credit they deserve. Additionally, they are eager to discuss concerns and errors the team has made to improve in the future.
4. Product managers can deal with unplanned work problems.
No matter how well a team plans its activities, there are always going to be some surprises popping up in the middle of the sprint, and the product manager and the team need to find an efficient way to deal with them. Unplanned work comes in many forms, such as emergency production bugs, data corruption, a small change in a requirement that stops us from launching a new feature, or an angry customer or stakeholder that we need to do our best to keep.
As you can see, there are countless possibilities, and the product manager is the team’s first line of defense. He or she should be able to effectively communicate the issue, put a plan in place, and do so cautiously to make sure that the team’s focus and morale won’t be affected.

5. They enjoy getting into technical discussions with their teams.
Being a technical expert with hands-on experience is not a skill needed for product management. The ability to read between the lines, take in the information at hand, and lead productive conversations with engineering teams is, however, indispensable. Without it, it would be hard for product managers to figure out why the team needs two sprints to show or hide buttons on a screen that has been there for four years and hasn’t been touched since then.
Product managers must work to gain a thorough understanding of the system architecture, how each component interacts with other services, and the technologies and tools the team is using. By doing this, they will have a better chance of getting involved in the team’s technical threads and knowing what system limits they need to work on or avoid until they deal with the team’s technical debt.
Understanding various software development processes and terminologies is essential, even if you don’t have hands-on experience with their application. A good product manager is aware of the team’s process for releasing new features, how production bugs are fixed, and what the evil term “CI/CD” is all about.
6. They can weather stakeholders’ storms and protect their teams.
There are a lot of ways to define the word “stakeholder.” From my point of view, a stakeholder is someone interested in the product in some way. This could be a customer, a shareholder, someone who has a say in the product’s direction and strategy, or anyone who will be affected directly or indirectly by changes to the product. Based on this definition, managing stakeholders has always been seen as one of the hardest jobs anyone could have, and product managers can’t avoid doing it.
Stakeholders will always want to have the features they ask for as soon as possible. This is where a product manager’s skills come into play. It is essential to provide the engineering team with a sufficient amount of time to discuss requirements and evaluate feasibility. After that, it is the responsibility of the product manager to vouch for the team’s decisions and estimated delivery timelines. Most of the time, product managers are dragged into conversations where they have to commit to a timeline. If they do this without making sure their teams are on the same page, it could lead to unnecessary pressure, a lot of context switching, and a lower level of quality in the result.

7. They are data-oriented people who speak the right numbers.
When it comes to numbers, we’re talking about the right ones, because if we measure the wrong things, it’ll only make the situation worse over time.
I’ve known product managers who gauged product success based on the number of contracts won and the number of new features released each quarter. These numbers are ineffective because they indicate nothing other than a lack of product vision. Better metrics and measures should pay attention to aspects like customer retention and acquisition rates, user satisfaction and reported complaints or crashes, the impact of delivered features, etc.
It is always difficult to convince a competent engineering team that ask the right questions about features or requirements that are supported by nothing but a product manager’s sense of urgency. The team should have the freedom to contest the necessity of a feature, asking for the impact in numbers and supporting data. The product manager should be ready for these talks and have put in the time and effort to gather these numbers and data for their teams, not to mention the market and user research that should have been done before this step.
8. They create well-written documents that explain almost everything.
The ability to create excellent documentation is one of the abilities I’ve observed in every reliable product manager I’ve worked with. How well a product manager can communicate concepts, problem statements, product vision, and a variety of other things to the rest of their team will largely determine how effective they are. It’s helpful to be able to articulate ideas and document them so they can be shared with engineers, sales reps, business stakeholders, etc.
These documents could save a ton of time and effort in explaining a product and instead give the readers the chance to absorb the information and work on it asynchronously, which is more efficient, especially for engineering teams. Everyone should always look to well-written user stories and PRDs (Product Requirements Documents) as their source of truth, not just the engineering team that is working on the implementation of the feature.

9. They contribute to the growth of more product-minded, autonomous engineers.
Not every problem that a product manager brings up needs a technical solution. No matter how technical the ideas or solutions are, a team’s level of excellence is always determined by how well they can come up with good ideas and solve problems. Team members should be able to challenge problems and modify the existing system to meet requirements with minimal technical modifications. Not only should they lead the “How?” phase, but they can also suggest changes to the scope that would result in greater value. Smart product managers allow their teams to participate in all phases and do not just see them as executors who arrive late to the product evolution phases.
Additionally, confident product managers give the team the room and degree of autonomy required to make tactical decisions and manageable scope changes that benefit them but don’t detract from the project’s overall deliverables. By doing this, the product manager won’t become a bottleneck who needs to be consulted on even the smallest changes.
10. They create solid GTM plans for product releases.
A go-to-market plan, also known as a GTM plan, is an important step to guarantee that the users you have in mind will be aware of the launch of a new product or feature. This plan should cover a wide range of topics, including who will use this feature, how they will be notified, and what the expected outcomes are. It should also contain a clear set of action items with their respective owners.
The team needs to be aware of what is expected of them during the development, release, and launch phases, so this plan needs to be open to changes as they go forward and visible to all stakeholders. This gives them confidence that they’re working to a plan and won’t be surprised by unplanned tasks like user provisioning or technical support.

Final Thoughts
It always takes time to build a strong team that performs well and whose members are confident in each other’s judgment and decisions. Product managers should receive the utmost support because they are the ones who carry the flame and light the way for their engineers. In addition, it is their responsibility to ensure that the team is focusing its efforts on activities that are beneficial to them and the organization as a whole.
Article written by Muhammad Hani, Thndr’s Head of Engineering, who is passionate about building products that matter.
Thndr’s all-hands meeting
During one of those weekly “all-hands” meetings at Thndr , where we get together to share the week’s updates, everyone was celebrating that around 86% of EGX’s (Egyptian Exchange) investor growth in 2022 was registered and signed up through our Thndr app (Android, and iOS). Amidst the general excitement, as usual, the engineering team had their minds elsewhere and were concerned about something entirely different. Ali, our engineering lead, was thinking about a technical problem that had been looming for a while and was considered a priority technical debt item that should be tackled sometime in 2023. Because of the tremendous increase in the app’s usage, he thought that it would be a better idea to prioritize working on it right away. This was the start of a good conversation that I had with Ali and Seif to figure out when and what to start with.
, where we get together to share the week’s updates, everyone was celebrating that around 86% of EGX’s (Egyptian Exchange) investor growth in 2022 was registered and signed up through our Thndr app (Android, and iOS). Amidst the general excitement, as usual, the engineering team had their minds elsewhere and were concerned about something entirely different. Ali, our engineering lead, was thinking about a technical problem that had been looming for a while and was considered a priority technical debt item that should be tackled sometime in 2023. Because of the tremendous increase in the app’s usage, he thought that it would be a better idea to prioritize working on it right away. This was the start of a good conversation that I had with Ali and Seif to figure out when and what to start with.

Hey, it’s Redis again!
Redis is a powerful in-memory data structure store that has become increasingly popular among developers for its speed, versatility, and ease of use. With its ability to handle data structures such as strings, hashes, lists, sets, and more, Redis is a great tool for solving complex problems in real-time applications.
At Thndr we rely heavily on Redis. Our use cases vary between caching, distributed rate limiting, Pub/Sub for most of our background jobs, and even as a persistent key-value store, among others. And while at first, it wasn’t an issue, now, with our growing user base, which grew by more than 400% in the last 5 months, we started seeing a substantial increase in our Redis latency.
We’re using AWS ElastiCache as a managed Redis solution. At the beginning of all of this, we had a single Redis server and database provisioned and used by all our microservices. Some of the data that lives in this database is used by multiple services, and some of it is scoped to a single service. This is the famous “common data coupling” anti-pattern, and gradually, we started seeing more and more issues with this setup, increased latency being one of them. First, we hit our instance bandwidth limit, so we went ahead and scaled our instance vertically so that AWS would give us more bandwidth. The problem was that we were wasting a lot of money as our CPU usage was less than 7% and our memory consumption didn’t exceed 22%. Nonetheless, this solution helped us become resilient for a while. We would still have some latency spikes in market hours that could go up to 1s+ (ideally, Redis should have a latency of 1 ms for writes and much less for reads), but we were coping.
We have a problem..
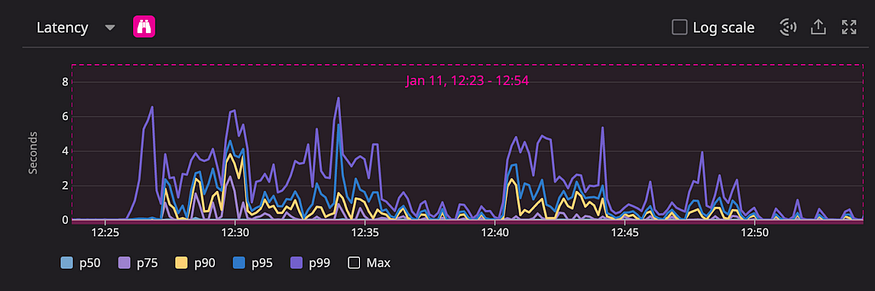
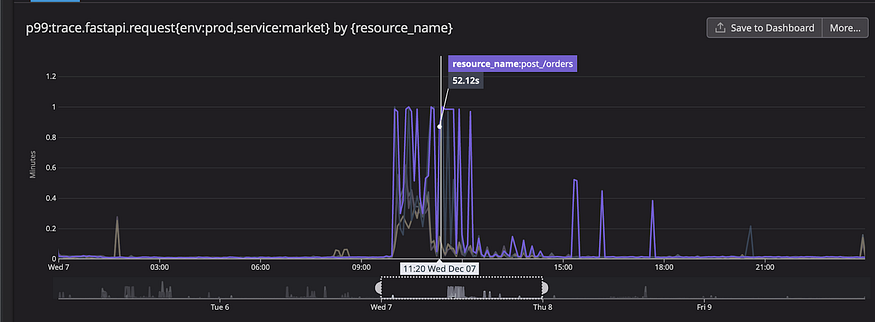
Soon after, this past December, we had our first big incident. It started with a huge spike in latency. Redis requests queue became backed up under the sufficient load, where the requests were being queued much faster than they were being processed. During the incident, Redis’ p99 latency reached the 40s mark. This affected our SLA and the user experience negatively. Our most critical services were affected, and the entire app became very slow. We saw 1+ minute latencies in some of our most important services. This was truly a wake-up call that relying on vertical scaling is not an option anymore and that it was time we addressed the root cause of the problem at hand.
The following graphs demonstrate how this had a significant impact on our latency throughout that incident.
Discovery
As mentioned before, we hit our bandwidth limit in Redis, partially because of our growing user base, in addition to some anti-patterns that we have scattered around the codebase, but more on that later.
Redis is single-threaded by nature, which means no two commands can execute in parallel. This might appear as an issue, but in most cases, network bandwidth and memory bandwidth are the bottlenecks as opposed to the CPU; thus, the performance gain from multi-threading is negligible. Since most threads will end up being blocked on I/Os, it wouldn’t justify the overhead of multi-threading, which includes significant code complexity from resource locking and thread synchronization and CPU overhead from thread creation, destruction, and context switching.
Nevertheless, when you use it to perform multiple key operations periodically on hundreds of thousands of keys, like we were doing at the time, it can take a lot of time to process and block the event loop until it finishes. These expensive O(n) operations, like mset and mget that we used to run, attempt to get more than 25k values at a time. There’s also the usage of the KEYS command, which is a very expensive and blocking operation and should be avoided at all costs in production and replaced instead with SCAN.
Through monitoring tools (we mainly rely on Datadog for this), we found out that unfortunately, our most impacted service is the market service, where all of the trading and most of the magic happens.
Operation “Split and Scale”
First, we started by splitting our huge, monolith Redis database into multiple ones, one for each service. We were able to end up with a Redis database per service for most of our services, except for a few where there’s this common data coupling issue that we mentioned in the intro. Already, by doing this split, we were able to give ourselves a lot of headroom and buy ourselves some time, to focus on the other contributing factors.
Then, we started looking into how to scale the different Redis instances, and naturally, we considered Redis Cluster. Since Redis operates with a single-threaded model, vertical scaling is not really a helpful option, as it is not capable of utilizing multiple cores of the CPU to process commands. So instead, horizontal scaling seems like a more plausible solution. Redis Cluster utilizes horizontal scaling by not only adding several servers and replication the data but also distributing the data set among the nodes in the cluster (what you’re maybe familiar with as sharding) enabling the processing of requests in parallel. What makes Redis Cluster extra special, however, is its sharding algorithm; Redis Cluster does not use consistent hashing, but a different form of sharding where every key is assigned to a hash slot.
Hash slots share the concept of using hashes or composite partitioning but do not rely on the circle-based algorithm upon which consistent hashing is based. One of the drawbacks of consistent hashing is that as the system evolves, operations such as addition/removal of nodes, expiration of keys, the addition of new keys, etc. cause the cluster to end up with imbalanced shards. In a way, this would have created more problems instead of solving them.
The way “Hash Slots” effectively solve this is by partitioning the keyspace across the different nodes in the cluster. Specifically, it is split into 16384 slots where all the keys in the key space are hashed into an integer range 0 ~ 16383, following the formula slot = CRC16(key) mod 16383. To compute what the hash slot of a given key is, we simply take the CRC16 of the key modulo 16384. Doing this makes the evolution of the cluster and its processes (such as adding or removing nodes from the cluster) much easier. If we are adding a new node, we need to move some hash slots from existing nodes to the new one. Same way, if we would like to remove a node, then we can move the hash slot served by that node to the other nodes present in the cluster. In return, this creates a much more balanced cluster, solving the issue with consistent hashing.
One thing to take into consideration though is that AWS Elasticache operates a little bit differently than Redis. So, for example, there is no sentinel mode, so sharding is always obligatory if you’re thinking of adding more nodes to scale horizontally. Also, cluster mode behaves a bit differently than how Redis normally does. Like for example there is no minimum limit of three on the number of nodes that a cluster should have as Redis does. So AWS Elasticache documentation should be consulted first before going through with it as a solution expecting it to behave just like Redis.
Another Discovery
We also looked at the library that we are using now to make calls to our Redis databases. We found that it was deprecated, and didn’t support Redis Cluster. Digging deeper into its source code, we found that it was also not that performative in terms of some multi-key commands. For example, running commands in a pipeline runs the commands in a for loop instead of pipelining the commands. We decided that we should look at other libraries that support the Redis Cluster, which are hopefully much more performative.
Another area for improvement was the fact that we use Redis as a Pub/Sub mainly to schedule celery jobs. In a nutshell, using Pub/Sub with Redis Cluster is generally a bad idea. As the client can send SUBSCRIBE to any node and can also send PUBLISH to any node, the published messages will be replicated to all nodes in the cluster. This makes Redis Cluster as a Pub/Sub solution inefficient.
The Solution
The first thing we did was replace our Celery jobs with Kubernetes jobs instead across all our services to mitigate the load a bit from Redis. An added bonus was that we have much better observability on Kubernetes jobs than we did on Redis jobs anyway.
Then, as mentioned before, our market service is not only the most impacted service, but it’s also one of the most important and most used services in our ecosystem, so we decided to start from there.
We wanted to try implementing Redis Cluster there first and monitor its performance. And since this is a big move, we took it in steps, so we first looked at alternatives to our deprecated Redis library. Our criteria for choosing this library were 3 things;
- Huge support from the Redis community
- Performative operations where for example pipelining is actually pipelining the operations and not just putting them in a for loop under the hood.
- Support of Redis Cluster mode and multi-key commands in cluster mode.
Obstacles along the way
One of the challenges that we faced while picking a library is that, for the aforementioned third point, most libraries didn’t seem to support multi-key commands in cluster mode, which are essential as they are widely used in our codebase (luckily, we don’t really care about atomicity when it comes to these kinds of operations). Thankfully, we found a suitable client library, and we were able to use it without introducing lots of changes to our code base. It’s important to mention that, in our case, it was relatively simple since our applications didn’t care about atomicity when it came to our multi-key operations, but in case the need arises in the future, we can always use hash tags, which can be used to force certain keys to be stored in the same hash slot. This should be used carefully, however, as it can easily skew the data distribution across hash slots and across nodes.
Moving Forward
As mentioned, we took this in steps. So we started by just deploying, taking out the old Redis library and replacing it with the one in the market service, which is much better supported, and making sure it worked well before switching to cluster mode.
Then, since we use AWS Elasticache for a managed Redis deployment, we created an ElastiCache cluster of 3 nodes with cluster mode enabled (using Terraform, which we use to define and deploy all our infrastructure) only for the market service. But when we started applying this in code on the market service we faced an issue along the way…
More Obstacles
Turns out Redis Cluster is not supported in the Datadog APM library that we use, and since monitoring and observability are two key components to anything that we do at Thndr, we couldn’t move forward. We faced a dead end and were contemplating what to do. Should we wait until it’s supported? Should we fork the library and build support for it ourselves? The truth is, we were really tight on time, and we were expecting a substantial jump in our app load any day, so we had to find a solution that worked now.
Monkey patching to the rescue! Even though monkey patching is not really the most efficient or aesthetically pleasing code to write and maintain, it was a fast and effective option. We were able to monkey-patch the library and make sure monitoring was working on our staging environment in around 30 minutes.
Showtime and Results
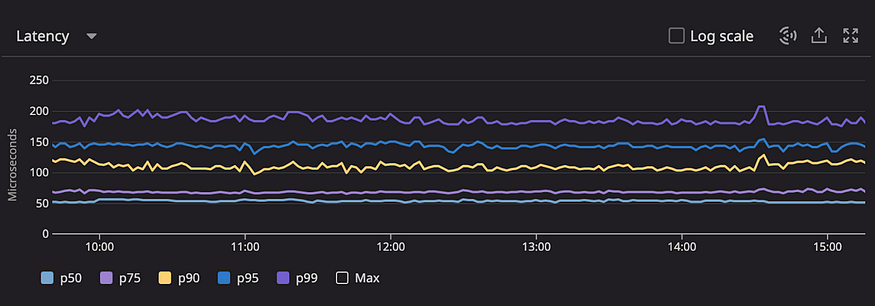
And finally, we were ready to deploy Redis cluster mode in one of our services and see it in action on production. Immediately upon deploying our solution to production, the results were immediate. The following graph was taken during market hours, and it shows Redis latency mapped just to mere microseconds!
Wrapping up
To sum it up, we discussed the problem, discovery, solution, and implementation of one of Thndr’s app’s technical debt items that had become a higher priority due to the app’s phenomenal growth in daily transactions and user base. At Thndr, we are firm believers in continuous improvement and doing things the right way. We also acknowledge that there will always be trade-offs and that technical debt should be prioritized during each iteration and at every level. However, we also know that there are many amazing projects and codebases for products that were not fortunate enough to continue. Every day, trade-offs are inevitable!